
AI
Six use cases, six thoughts

This is the beginning of a series in AI. Forthcoming posts include how to think about AI’s impact on NYC’s labor market, what good use of AI in NY government looks like, how to change the pace and nature of legal reform in response to AI, and more. If you want to discuss any of these things with me, I’d love to hear from you.
Table of contents

Introduction
This is my first post on artificial intelligence, but it will certainly not be my last. The large and varied set of tools collectively referred to as “AI” have already changed many New Yorkers’ lives, and that fact will only accelerate. What many New Yorkers—in government, private industry, and wider civil society—need now is sense-making and meaning-making around AI.
Sense-making is the process of making sense of what is happening, not just on an individual level, but socially as a city and wider society. It answers the question What is happening?
Meaning-making is the process of taking that which is understood, and then finding out what it means for those involved. It follows sense-making, and it answers What does this mean for me, for my family, for my city?
The goal of this post, and all the posts on AI that come after it, is to productively improve New York’s capacities of sense-making and meaning-making. At the moment I see too many failures to do either, or do them well, and those failures drive pessimism, feelings of impotence, and bad policy. But we—you and I—can set New York up for a better future, starting with better sense-making.
So, regarding AI: What is happening?
One could answer this question in grand terms. What is happening to our nation and human civilization? What is happening to entire generations? What is happening to our economic system? But this is a bad place to start. Why? (1) It prompts people to skip over personal understanding of AI and jump straight to unanchored societal theorizing. (2) It presents the world as happening to people, and gives them no agency. (3) It doesn’t help people improve their lot or realize what they could do.
I see the “grand sense-making” fallacy all the time in politics. People avoid learning how the political system works in real ways, they construct terrifying castles of theory upon that lack, and then trick themselves into thinking there’s nothing they can do about some inevitable future calamity.
My solution to the lack of political sense-making was to start teaching people about how the political and governmental system worked in a nuts-and-bolts way, anchored in things they could see in New York City. I, of course, have my own grand theories about politics, and actions that I take in pursuit of those, but those are separate. This approach has worked, and continues to work.
My approach to sense-making around AI is similar, but not the same. My knowledge about AI is not the same as it is in government. I am not, nor have I ever been, a professional software engineer. However: I approach AI tools in a nuts-and-bolts kind of way, trying to understand what is practically possible for both work and play first, policy and society second; I think it must be this way, because one must acquire sustained personal and social fluency with AI tools before legislating or otherwise grandly theorizing about them.1
So this post is not grand theorizing about AI. It is a list of six personal use cases I have for it, and a list of six ideas that I have about AI grounded in my own, and others’, personal and professional use of it. Grand theorizing can, and will, come later. But the nuts-and-bolts approach is foundational.
I hope this helps anyone make sense of things.
Use Cases
Each of these six use cases is “regular.” AI has helped me with my health (I’m not the only one) and life in more dramatic ways, but I want to stay anchored on everyday type stuff people will encounter, especially at work. If I were just making a bulleted list of stuff I do with AI, it would look similar to this one!
1) Data visualization
I created a data subdomain of the Maximum New York website at data.maximumnewyork.com. I created the website, and everything on it, by using Claude Code in my Mac’s terminal, with occasional assistance from other tools. I first downloaded Claude Code when I was visiting my Mother for Christmas in December 2025. I’ve only been using it for about four months, but I can no longer envision using a computer or any of my major MNY-related workflows without it or other agentic tools.
All the output data still has to be validated by me to make sure it’s correct, but the means of visualization you see on the MNY data site are far beyond my abilities of just a few months ago. Either each viz would have taken a prohibitive amount of time, or I simply wouldn’t have been able to figure it out on any reasonable timeline.
These data visualizations have increased interest in my work, driven curiosity in others, and have generally been a boon. Tal Roded has also created a data site for his Substack, if you’d like to see another proof of the concept.
Things have come a long way since I used ChatGPT to create Python scripts to help analyze all of NYC’s 2023 local laws! That whole workflow is now obsolete by quite a long shot.
Here’s an example of how I visualized NYC’s budget over time:
2) Slides
People have been making PowerPoints with ChatGPT for a while, and many people have found them to be kind of mediocre. However, using AI to give a first pass on slides can save a ton of time, and you can touch them up if you need.
This is not actually how I make presentations with available AI tools, especially not after OpenAI’s release of their new image model last week.
A common workflow is: ask LLM to make pptx given some context —> iterate with LLM or manually —> finalize pptx.
This is my workflow: ask gpt-image-2 to generate a series of png images that will be my presentation (either via API, agent, or ChatGPT web app) —> iterate on images with gpt-image-2 —> finalize presentation by having an agent/ChatGPT combine the images into a pptx file.
OpenAI’s current image generation capabilities are extraordinary; if you haven’t revisited them in the past week, your estimation of them is out of date. If your goal is to make a visual presentation, then (so goes my thinking) you should make your presentation with the best available visual generators. Many people instead think that they should make their visual presentation with something that can make presentations. But that confuses the means for the end. Get the great visuals first, then make them into a presentation. Sufficiently advanced visual generators, which we have, can create what you need in the format of a slide deck.
While there are presentations where this approach wouldn’t hold, I will ask the reader to try generating slides as images, and iterating on them as images, using the new image model built into ChatGPT. See how that compares to what you get if you try to prompt a pptx output first, even with the same context. (Claude Design is a whole separate conversation.)
I have included two slides below to illustrate the difference between image-first slide generation, and slide-first slide generation. I gave ChatGPT (the web app, $20/mo version) a prompt to use my post on mayoral executive orders as source material, and to create an explainer presentation based on it. Not only was the image-based deck created about a minute faster, it was much prettier out of the gate. These were not one-off results, and the same principle applies to any visual use case (social media, general fun, and so forth).

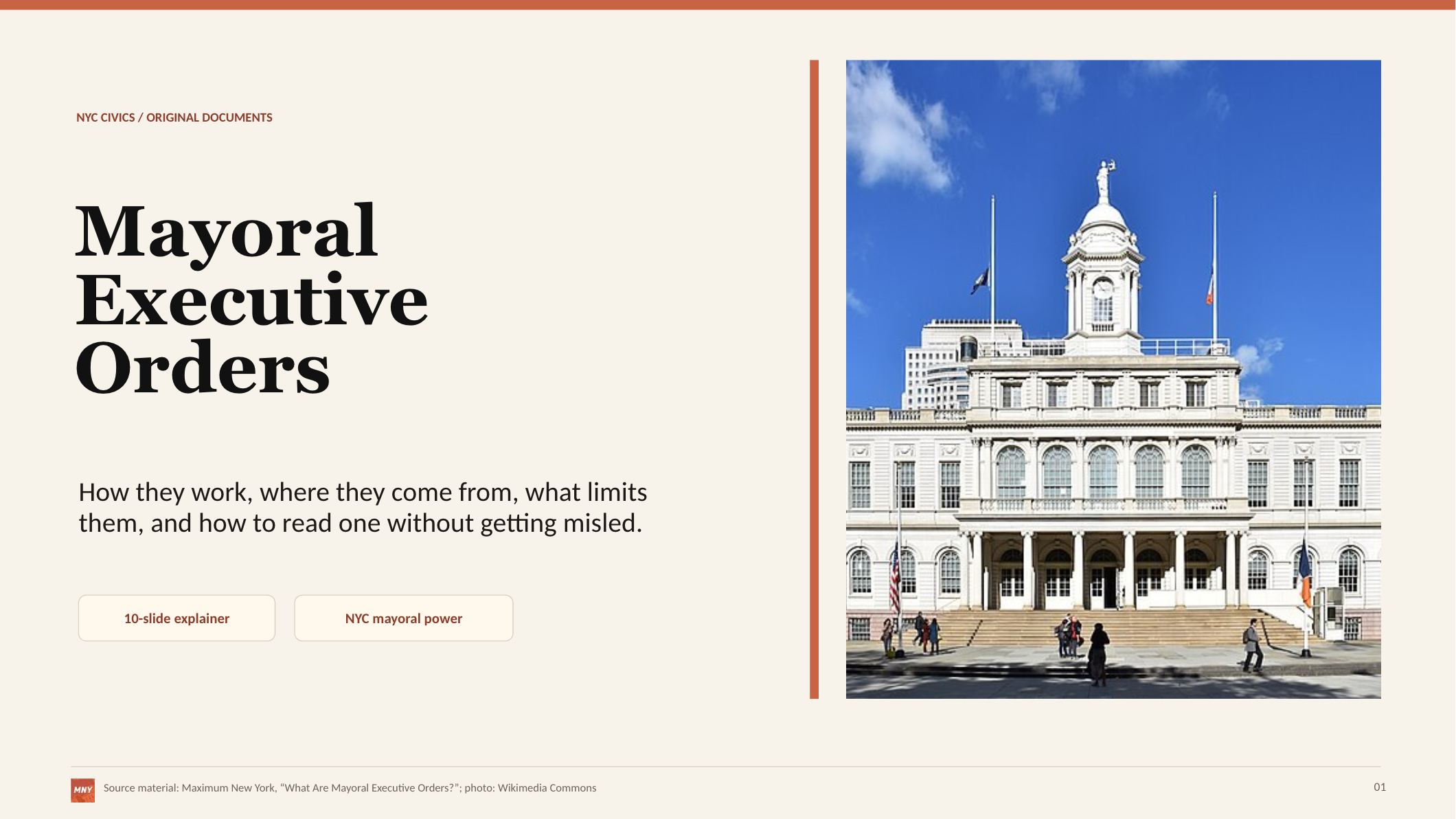
3) Personal website
I’ve had many versions of danielgolliher.com over the years. My personal site has been a WordPress site (both self-hosted and otherwise), a static Jekyll site, a Carrd site, and more. In recent times it’s just been a dead link, because most of my online presence lives in a pretty consolidated fashion on social media and on this blog. But I really did want one central place on the internet that compiled everything I was working on. The frictions associated with setting that up and making design choices got the better of me.
That is, until I decided to give the task to Claude Code (Opus 4.7, Max plan) about a week and a half ago. I was pretty quickly able to spin up a site that looked and functioned as I wanted, with an almost frictionless workflow to edit anything in the future.
Now my personal website is a virtual library that I invite you to visit.
4) Video game maker
I’ve actually made a few video games with both Claude Code and Codex at this point, but the first one I completed was an 8-bit video game engine (8bit.danielgolliher.com) that allows the user to customize their own 8-bit enemy-wave style of game. They can share it too, or play 1v1 in the browser if they have a friend they want to play directly against.
I took this one step further by buying two cheap, generic video game controllers on Amazon. I added functionality for the controllers, as well as standard keyboard controls.
5) Simba the receipt printer
I bought a receipt printer and programmed it to print whatever I want! I named the printer “Simba,” because whenever I demo him I have to hold him up (Simba him) for everyone to see. Here’s a video I posted of him on social media last month:
I originally did this just to see if it was possible. I was sitting in my apartment, and thought it would be cool to print little commendations for students in class when they successfully recited memorized content. Then I thought about receipt printers. Then I thought Claude Code could probably help me communicate with those printers, even if they weren’t compatible with my Mac out of the box (and Simba was not).
Fast forward, and Simba has enlivened office hours, class, tech demos, and just regular life. The custom software I made to use him creates print previews before the print job executes, and Claude calls the OpenAI API for image generation or certain data tasks for a print job. If you’re wondering what you could use a small, portable printer for, ask yourself this question: “What would change if you could print on-the-go, arbitrarily, because you always had a printer in your bag/car/wherever?”
Simba is a thermal printer, so he doesn’t need ink. And you can get versions of him that connect to a computer or phone wirelessly, and are powered via battery. Pair this with custom software that you either type or talk to, and you have arbitrary printing.
I’ve printed off copies of my Substack essays with a QR code on the paper so someone can go get it immediately on their phone, copies of the U.S. Constitution, anything that ChatGPT can generate in an image, selfies with my webcam, sheet music, meeting summaries, and so much more.
Simba now has several siblings (Simbalings) in my apartment, and they all do different things; they perform a mix of work and play, and I’m still expanding how I think about them. One of them just prints posts from the accounts of the major AI labs and a few of their engineers. Other people are experimenting with arbitrary printing via thermal printers too (see the thread on X below).


6) Research and retrieval
Web-based LLMs are often far better than standard search through Google, especially if you, like me, do research that requires older or more obscure material. You can describe the nature of the thing you’re looking for (e.g., a New York Times article from roughly 1915 that describes X) and probably get it, whereas Google would have absolutely failed at the task.
[Side note: I still regularly get help from the librarians and archivists of the New York City Municipal Archive, who remain the champions of sourcing material.]
When I’m writing a blog post, I often half-remember something that I read in the past that’s relevant to my current writing. Last week I was writing something about the often simplistic distinction between “public and private” regarding state capacity, and I remembered I’d read something recently that had a sentence like “sometimes state capacity exists outside the state.” However, I couldn’t immediately remember where I’d read it. I gave Google the following context in various formats: “Substack article, ‘state capacity often exists outside the state,’ from 2025 or 2026, something about water projects.’
Google failed. Claude got it in one shot—it was Connor Tabarrok’s “Water and Sanitation in the Developing world.”
Beyond obscure PDFs and perfectly modern Substacks, LLMs have also allowed me to find niche memes. Two night ago I was talking with a friend and we wanted to pull up a meme we’d sent back and forth a few times, but neither of us could actually remember enough about it for Google to work. Even worse, it was prohibitively far back in our DM history to just scroll until one of us found it.
So I described the meme, and gave that description to the web-app version of Claude, ChatGPT, Grok, and Gemini (all of these were at least the $20/mo version). Gemini found it almost immediately, Grok found it after thinking for a few minutes, and the other two failed even after extra prompting.
Ideas
1) People are becoming more like software engineers
I would therefore expect more members of the general public to adopt, on the margin, the dispositions, preferences, habits, predilections, and the like of software engineers. —Dean W. Ball, “Among the Agents: How I use coding agents, and what I think they mean,” Hyperdimensional (January 8, 2026).
As more and more people use AI tools to do things on their computers, they will naturally start to adopt the tools, cultures, frustrations, and opportunities of people who have been using their computers deeply for a while: software engineers and their tinkering humanities brethren.
One obvious manifestation of this phenomenon has been an uptake in GitHub usage. GitHub is a way to host files on the internet (which is really all that websites are), and it is built around git, which is a version-control system that tracks changes to those files. You can use it by yourself on your own files, or as part of a team to manage the contributions of many people to the same set of files.
Now, many people who have never really coded in their lives are suddenly using GitHub! They create dashboards or other cool websites with agentic tools like Claude Code, Claude helps them set up a GitHub account to store and manage the files for their site/app, and then Claude helps them use GitHub Pages to turn those files into a website with a URL they can send to anyone! By default, those URLs look like <username>.github.io/<page name>. For example, I made a map of schools in NYC with low enrollment that you can find here: https://danielgolliher.github.io/nyc-school-map/ (note: I’m still working on the project; it’s in a very draft form, but you can see the GitHub Pages URL format).
As people learn more about GitHub (and Vercel, and Netlify, and Railway, and so forth), which agents like Claude introduced them to, they learn how to actually use version control for their files, and why that matters: you “save” a version of your files as you work on them with an agent so that, if the agent messes them up, you can just go back to your last “save point.” It’s the same thing people do in video games: before you try to catch Mewtwo, save your game in case you accidentally knock it out. You can just restart the game and try again.
If you’re reading this and you haven’t yet had success setting up a site or app, or you feel like you’re missing a key piece of information for agents to really click for you, you’re likely in the swamp of friction. There are probably a few key ideas like “file directory,” “version control,” “hosting,” or “DNS” that are between you and the success and clarity you’re looking for. You need to find someone who can drag you through the swamp of friction to the other side. Maybe you can find that online somewhere, but if you want a more structured path and deliberate instruction, I’m happy to arrange 1:1 work (daniel@maximumnewyork.com).
2) Growth in AI tool proficiency primarily comes from personal use, not professional use
While there are clearly exceptions to this idea, especially among entrepreneurs who blend the personal and the professional more than most, fluency with AI tools for most people comes from personal use.
Most people work in professional settings that restrict the use of AI tools on the job. Sometimes that’s just because those workplaces are slow and incurious, and sometimes there are very good reasons to be more deliberate about integrating AI tools into an office. If you work with confidential data, you will not want that data to enter an LLM’s general-consumer training data if you use an LLM to analyze it. And, despite the utility of some vibecoded applications, you would want to verify whether they are secure before letting confidential data flow through them.
And so: the greatest capacity that most individuals have to explore AI tools and their possibility is not at work, but in their personal lives. Individuals can also make their own risk assessments about what they are OK doing, like uploading medical records and results directly into Claude Pro for help researching them.
Ideally, they can then bring their increased skills to bear when helping their workplace or other institutions navigate the AI landscape. In fact, this seems to be the most common way of upskilling a workplace at the moment: people explore widely in their personal lives, and workplaces reward that (or not) by doing relevant administrative work on their end to integrate reasonable AI tool use in their professional context.
The most forward thinking workplaces have an ecosystem-based view of their AI tooling. They know their people are already using AI widely outside of work, and they know that many of their employees are far beyond what they can offer in the way of traditional “upskilling.” They acknowledge this, and do not make employees hide their outside use of AI. Crucially, they will expeditiously do the audit and control work necessary to expand how their employees work with AI on the job.
3) Play and informal social exchange drive improvement in AI tool usage
Although I spend a lot of time on my own exploring and using AI tools, much of my improvement comes from existing within social groups of people doing the same thing. We get together, talk about what we’re doing, trade notes, have fun, and think about the future together. Often we aren’t getting together specifically for “AI reasons.” I’m just good friends with people who have integrated these tools into their lives, and we discuss them like we discuss anything else in life. We all have different backgrounds: some are software engineers, many are not. But we all bring unique perspectives and use cases to the table, and we all learn from each other.
I’ll give you two examples of how this plays out for me personally.
The first is that I work and hang out at Fractal Tech. That place is crawling with kind, curious, ambitious people looking to improve their individual and societal lot through computing. I learn a lot from doing demos of my projects at demo nights there, seeing what other people are doing, and having long, extended conversations with people like Andrew Rose who have been thinking about the technical opportunities in computing for the betterment of human living far longer than I have. You can see, comparing my writing with his, that we approach AI from different starting points.
The second is that I work and hang out at the Manhattan Institute, where I am a Fellow. As an institution, their leadership understands the great, real promise of AI, and they’re implementing it in a practical way on the ground. I conduct “AI office hours” there, and people just drop by to ask questions or see what I’m working on. It’s been immensely fruitful. The slide design via gpt-image-2 only came about because someone at MI asked me what the best way was to touch up a slide deck with AI; I hadn’t really been thinking about that, but I had seen that OpenAI’s new image model had dropped a few days prior. That question prompted me to see whether it could handle a slide—and it became my default immediately. There are tons of day-to-day use cases that I’ve acquired (and diffused) simply by batting ideas back and forth in an interested and motivated workplace, on top of MI’s more involved, substantive policy work about AI. One reason why I’m happily a Fellow there is because their broad stance of urban pragmatism and innovation is carrying directly over into their increasing work on AI in New York City.
Social groups create pools of implicit intellectual dark matter and motivation that are hard to replicate with formal training or explanation. Just like a lot of AI learning is currently coming from outside the workplace, a lot of institutional or cultural AI learning is coming from social groups that explore it together—which can be workplaces if they’re forward thinking enough!
4) Learning to Google, reflexive retraining, and getting out of your own way
Google Search launched in 1998, and the verb “to Google” was used on Buffy the Vampire Slayer in 2002 (see this nice history of the verb for background).
Nonetheless, most Americans wouldn’t get in the habit of reflexively Googling something—typing their plain English question into a browser bar, or on Google.com itself if you go back far enough—for a while. People still argue about things that they could easily look up.
It takes time to retrain your mind to work in different ways, and it takes time to adjust to new capabilities. Nowadays, many people do not have a conscious thought process that goes “I should Google that question instead of going to the library or calling a reference number.” They reflexively type their question into a browser and hit enter. It would never occur to them to do anything else, just like, prior to the habit, it wouldn’t have occurred to them to Google the information. Reflexive action must be trained. Anyone who has learned to play an instrument, speak a new language, or work a machine tool can tell you the same thing.
Well, AI tools have brought us all to the doorstep of a massive change in our reflexive response to constraints, challenges, priorities, and possibilities. The new reflexive instinct is not “ask the machine to see if it knows.” It is “can I do anything that any human has done, can I know anything any human has known, can I go beyond both of those?” Each person, with agentic AI tools, is far more capable today than they were just a year ago.
Googling is a reflexive query. Using AI tools is reflexive doing. But it takes time to get up to speed, and to cultivate an intuition for this mode of operation. It takes false starts, half-habits, and just fiddling around.
I have sticky notes around my apartment that say “Ask Claude.” Why? Because my mind is still attached to an outdated understanding of my own abilities, constraints, and priorities. If I’m writing something and think of a great way to visualize it, I used to think this: “This will take me hours to put together, let alone make pretty. It is not worth the opportunity cost for this.” Sometimes I still think that, and don’t add the visualization I want! Of course, that understanding of constraints is no longer true. Now I can have Claude Code or Codex make that visualization for me in minutes. This general way of approaching constraints is true of everything. AI tools open a completely new way of existing in the world, but people must train new reflexive responses to constraints—otherwise they will still do the equivalent of calling a reference number and hoping for an answer.
That said: AI tools are not just making me use AI tools more. The changing nature of my reflexive response to constraints—“I bet I can do it” on a far larger scale than before—is spilling over broadly into my psychology. I like to think that I was a can-do type of guy before I had agentic AI, and I think that was true. But it is certainly even more true now.
I am generally far more willing to just try things and figure them out. Sometimes with AI, sometimes not. The habit is being reinforced generally.
A prosaic example: I wanted to see if I could automate a certain way of handling data in Airtable. I went to Claude to see, but realized Airtable has native functionality that does exactly what I want, and that that would be better than making something custom myself. Claude pointed me to this functionality, and confirmed it was as easy to do as I hoped. The end result here had no AI, but AI radically reduced the mental friction that occurs when one doesn’t understand something and needs to learn. My reflex is becoming “there’s a way, and you can iron it out faster than you think, commence doing.” I put off far fewer technical tasks outside my primary areas of expertise too. I just do them (I replaced a doorknob with Claude just the other day).
All this said: I don’t think you should start to use AI tools now “so you don’t fall behind.” I don’t really think that’s exactly how this will work, or is working. The tools themselves change too much, too quickly. I think people should use them because they can better their lives, individually and socially. My exhortation is to pursue a good, not to outrun a bad.
5) Be concrete
The word “AI” does not mean one thing to everyone. I’m not here to give you a definitive meaning for all time, but I do think each person should iron out what they mean specifically when they say “AI,” and that they should find out what others mean by the word.
This is being concrete about it.
In my government classes, concreteness is a requirement. Phrases like “the government should do X” are not generally allowed. You have to say which part of the government, by which legal mechanism, whether it would take a new law, and where that law would be written down. You have to get concrete enough to be operationally useful, and aspire to that standard.
The same is true about AI.
“AI will take our jobs!” What do you mean? Is Claude going to personally hand you a pink slip and steal your nameplate? That is not concrete enough to be operationally useful! Do you mean “agentic AI, like Claude Code, will combine design and production?” That’s better. Or do you mean “Claude Code allows a principal or senior researcher to mock up the research project they want to their standards in a few minutes before handing it off to a junior to do more routine audit or cleanup tasks to move the project forward; this is a reversal of the usual workflow where the principal would dictate general terms to the junior, who would produce the mockup to then undergo substantial iterative comment by the higher-ups to get what they want. This looks different in academia, manufacturing, and…” Now we’re getting somewhere useful and real.
As in politics, many people have a tendency to speak grandly, or to speak with abstract terms that are disconnected from any real or practical understanding. There is always a more concrete, practical, reality-oriented way to speak and think. It is this latter mode that will facilitate good policy tailored to facts on the ground. But to speak this way about AI, one must be a regular user of it, and talk with others who use it in different ways. You can’t just fiddle with it a little and be done. The technology is changing too quickly for that, and it takes too many diverse forms.
6) Hallucinations are bikeshedding
“Bikeshedding,” or Parkinson’s law of triviality, says that people will spend a disproportionate amount of time on relatively insignificant details of something if that’s the only thing they understand about it. In context, he was referring to a committee meeting about the construction of a nuclear reactor. Most of the people in the room had no expertise to offer about the reactor itself, but pretty much everyone felt comfortable offering their opinions about the appearance of the bike shed that reactor employees would park their bikes in. The result is meeting after meeting about a bike shed, which delays the actual reactor.
Discussing AI hallucinations—when they make things up—is quickly becoming a means of bikeshedding. It is one legible detail about AI tools that many people can wrap their head around, and they are focusing on it far too much.
I’m not saying that people shouldn’t be aware of hallucinations and take steps to control for them. But they are a known problem, and in many use cases users can take straightforward steps to control for them. Many workplaces that use AI tools have an increasing array of audit functions to double check AI output. So the problem of hallucination is changing by the month: it just doesn’t happen as much for most people, and the audit functions on AI output are increasing in quality and quantity.
Federal Magistrate Judge Maritza Braswell (U.S. District Court for the District of Colorado) is one of the most public, forward thinking members of the judiciary on this topic. Here’s what she had to say about hallucinations in the daily work of the federal judiciary on April 15, 2026:
I hope we dim the spotlight on hallucinations soon. I think the conversation around hallucinations has taken up so much space that we're focused on a problem that, frankly, is sort of the least of our problems. Hallucinations are visible — you can spot them. I use Quick Check in my chambers as a final check when I'm concerned about something. If you have your Westlaw tab open while you're doing your work, it's pretty easy to pop a citation in, make sure it's there, identify the right pin cite, and make sure it says what it says. My policy talks about the importance of reading every case before we rely on it, so there are ways to mitigate against that.2
The policy that she mentions above is the AI policy she has promulgated for her court, and the lawyers, litigants, and others who interact with it. She strikes the right tone: hallucinations are real, but they are not the focus:
In recent months, much of the conversation about Generative AI (GenAI) has focused on hallucinations: instances when a GenAI tool invents quotes and legal authority. These incidents are serious and deserve attention. But when the narrative begins and ends with hallucinations, it limits the kind of thoughtful exploration that’s essential for responsible innovation. It also risks distracting us from other, equally important issues raised by AI’s growing role in law and society
Hallucinations are new, but inaccuracies are not. Hallucinations in court submissions are a serious matter. But all inaccurate statements made to a tribunal, regardless of how they were generated, are a serious matter. Cutting and pasting from a template without verifying the content, for example, could similarly result in inaccurate statements.
Hallucinations are only one part of the conversation. Hallucinations have captured our attention, but they are far from the greatest AI-related challenge. The legal profession, and society more broadly, will have to confront deeper and more complex questions: how to safeguard privacy in an era of pervasive data collection, how to detect and prevent (or at least interrupt) bias, how to protect against misinformation/deepfakes/fabricated evidence, how to ensure humans retain meaningful control and autonomy over decisions that affect our lives, how to prepare the next generation of lawyers and judges for this new environment, and much more. Beyond those immediate concerns lie even larger questions about alignment, safety, and the long-term trajectory of increasingly powerful AI systems. Those issues warrant thoughtful engagement and remind us that hallucinations, while important, are only one part of a much larger conversation about the responsible integration of AI into law and society.
To me, when someone focuses too much (or solely) on hallucinations when discussing AI, it is an indicator that they are not regular users of the technology, and that they are certainly not up to date on it. Worst of all: they are likely not thinking about its upsides enough.
Lean In, Surf the Wave
AI is here, it is happening, and it will keep happening.
It is the industrial revolution. It is electricity. It is republican government. It is the internet. It is all of these things together, and more. It will transform human civilization, and has already begun to do so.
But, as I said at the top of this essay, I’m not talking about the grand sweep of AI and human society today. I just want people to walk away understanding that it is a real tool(s) that they can embrace, understand, and use to improve how they live. If there are downsides, they can be addressed. If there are upsides, they can be realized. Really, the only choice is to do this on purpose and explicitly, or otherwise.
This exploration and integration of AI is best done with friends and community. And it is really only by cultivating broad-based, competent usage that we can best craft enduring, fair policy and other architectonic societal rules anyway.
If you feel like you’re on the outside looking in regarding AI, come to MNY Office Hours and we’ll see what we can figure out, or come to any MNY event. Hang out at Fractal Tech. One of the best ways someone can help society acclimate to AI is to understand it themselves and personally improve their lot, and to help others do the same.

Or have a validated intellectual proxy, in the form of a person or a community of practice.
You can find these comments shortly after the 27:00 mark on this video from the National Center for State Courts, “How judges are using GenAI.” (April 15, 2026)
Best post about personal AI use on the internet as of this moment.
I'm about to "borrow" all of the little printers we have around the office and create my own Simblings - that is such a fun creation!
Also as lovely as the image-first slide you made was, all my brain notices is the impossibility of the buildings depicted 🙈 I think the building with columns is a mashup of the court house and the Municipal Building? One World Trade is north when it should be south. And what looks like 432 Park Ave is way too visible in the Civic Center. My ChatGPT would get a talking to if it gave me that hahaha.