


Anatomy of an AI-Driven Civic Tech Product
An interview with Vikram Oberoi // How do you parse *every City Council meeting* with AI // "The transcription service has never heard of NYCHA. So it always transcribes them as 'NITRO'"

I often get asked how to build software to make the government better, or hold it to better account. The arrival of ever-improving AI tools has accelerated this trend. And while I can provide part of the roadmap for doing that, at the end of the day I am neither a soft- nor hardware technologist.
So I sat down with Vikram Oberoi, a New York-based software engineer who created citymeetings.nyc (“citymeetings”), a site that breaks down lengthy public hearings at the New York City Council. In his words: “This work turns a 7-hour meeting with presentations, Q&A, and extensive public comments into an artifact anyone can navigate in 15 minutes.” Vikram sees immense possibility in AI review of public records, and walked me through the process of creating citymeetings.
His site is being used by people within government, advocates and lobbyists, interested citizens, the city council Twitter/X account, and more. It’s moving the needle on government accessibility, and a great example of what one person with AI tools can do that previously wasn’t done at all.
I spoke with Vikram to understand:
How citymeetings is different from what we have right now?
How was this product developed, and over what timeline?
How did you get users, who are they, and how did they find citymeetings?
Do you need to know how the government works to build for it?
What advice would you give to others who want to build something like citymeetings, and where do you see it going next?
What is citymeetings?
It’s a site where I use AI to break down really lengthy city council meetings into short, summarized, linkable segments. So instead of watching hours of footage or reading hundreds of pages of transcripts you can go to citymeetings and figure out what transpired pretty quickly, or you can find what you want in much less time.
How is that different from what exists now?
Right now the city council’s website gives you raw footage that you have to watch or scrub through to find the thing that you want; this video comes out almost right after a meeting is over. Or they put out human-produced transcripts, which are great. Those’re usually out a few days after a meeting, although it can be longer.
I use machine transcription, which is a relatively solved problem today, to transcribe a meeting based on the video, and I break it down into linkable “chapters” so you don’t have to watch all that footage or wait and read the transcripts to figure out what’s going on.
And the user interface for citymeetings is different from Legistar, the city council’s site / legislative management tool you’d otherwise have to get all the info from?
Totally, it is. Legistar has a learning curve to it. It can be really frustrating, it looks really old, and it doesn't work on mobile.

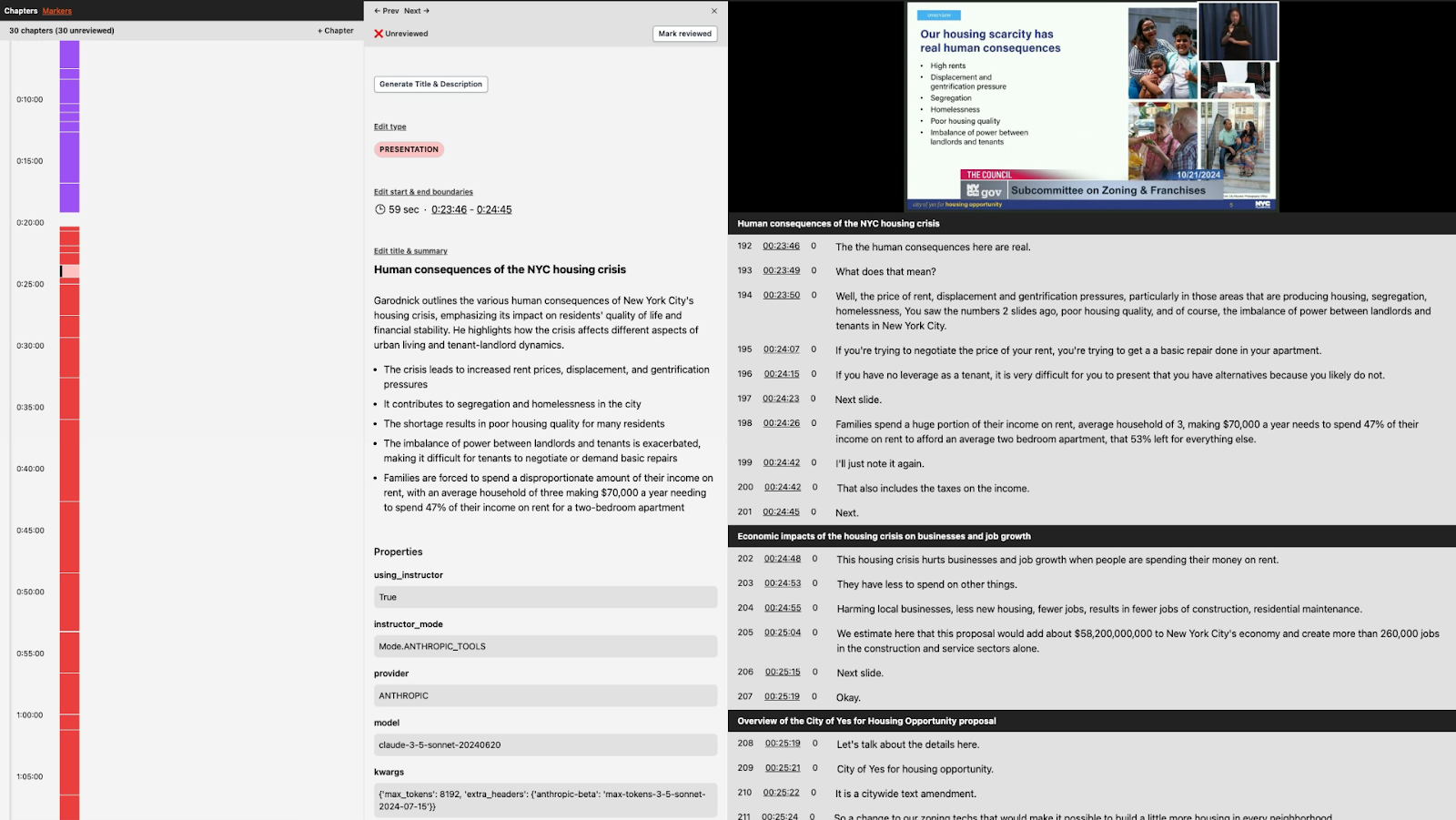
I keep it as simple as possible, with a list of meetings in chronological order. You can click on them, and each has a list of “chapters.” These are the list of short segments in chronological order within the meeting—council member questions, public testimony, remarks from agency officials, and things like that. And you can filter by the kind of chapter that you’re looking for.

It’s very clear what you’re looking at, and it allows different users with different needs to quickly get what they’re after.
Some are very keen to understand what legislators are saying and what positions they're taking; they can go to the Q&A or remarks chapters. There are some that want to know what the city agencies are saying. So there's a label for that, that just says “agency testimony.” And then there's some that just want to do public opinion analysis or see testimonies at large, and so on.
I guess another key difference between this and Legistar is that it's linkable, and at a very granular level; this is just using the internet the way it was designed to be used.
How does AI come into this? You can answer that in a few ways—how does AI come in as a tool, and how does AI come in as part of the user experience?
AI plays a really critical role in being able to build citymeetings. It might not be immediately obvious to people who visit the site, and that's somewhat by design. I'll have more to say on this later, but I don't think that presenting users with chatbots or empty text boxes is an effective affordance for most people. I think it's confusing. People don't know what to do with it. What I wanted to do was create something that people already know how to interact with, which is just links and content, although the way these are generated is through my AI workflow.
Tell me about your AI workflow.
I use AI as help—to help me break down these one, two, even 15-hour hearings into chapters so people can get to the exact three-minute chunk they care about, as opposed to scrubbing through 15 hours of footage. And it took me months to get to the point where I was capable of doing this with AI.
And a critical aspect of this is that I use human-AI teaming. I don't rely on the AI to create the output entirely. It's another thing that we can talk about more, but I don't believe that is a great way to use AI today. I also don't think it's going to be a great way to use AI in the future, even if you assume amazing developments in AI technology; if you just use AI alone, there's human judgment and your desires and goals that you didn't fuse into that process. citymeetings is the product of me, and there's a lot of preferences that go into what I create there.
As to the way that I use AI more specifically…My methodology has changed pretty drastically since I gave my talk at School of Data in March. (I annotated all my slides, so you can take a look at what my methodology was then.) I think it's a good talk to watch if you want to understand broadly how I use AI. But here's how it works today: The first thing I do when I get a video of a meeting is transcribe it using an AI transcription service.
I haven’t built a ton of automation to pull these meeting videos down, I just look at the city council calendar, because I only do the city council now, and I think “Great, I’m going to have to do a little bit of human-AI teaming work today.” When I see that a meeting is done, I’ll run a command to pull the video down, do the auto-transcription, and use AI to identify all the speakers in that meeting. That’s step one. That is critical context for later steps in the meeting breakdown process.
Once the AI identifies the speakers, I actually review each of them manually right now. That is currently the limiting factor in this process. It wasn't before. It's very time consuming, and I have ideas around how to improve it also using AI and various pieces of automation. But I do review it manually, because transcription services are not perfect at getting people's names, or government entities, or the alphabet soup of government right—like the transcription service has never heard of NYCHA. So it always transcribes them as “NITRO”. So I have to fix stuff like that. And I do take the integrity of the content on the site quite seriously.
I put a lot of effort into getting names spelled correctly and getting the roles and the entities right. There's an element of exactness that's required for people to build trust in the content.
The second thing I do is break the meeting video and transcript down into chapters. First by identifying the major parts of the meeting myself, and then having AI identify the subcomponents of those parts, which are chapters.

I have to help the AI here, because it can’t do it alone. You can see for yourself at home. If you want, you can take any long city council transcript and say to an AI tool “break this down into chapters.” You can write a long prompt, like 1,000 or 2,000 words on your ideal breakdown. I guarantee you it's not going to do as good of a job as citymeetings.
If it could, this project would be much easier. I give the AI a leg up by telling it where the different parts of the meetings are; I have a UI that allows me to click around and mark where opening remarks are, where agency testimony is, council questioning, public testimony, etc. That takes me about five minutes for every meeting, and different meetings require different sections. Land use looks a little different, but the process is the same.
Then I’ll ask the AI to extract markers within those sections, which is where the chapters come from; I use a timeline of the meeting to review the marker designations, and it only takes a few minutes. The AI is prompted to identify things like when a new council member takes the floor during council questioning, or when a new member of the public speaks in the whole public testimony section. I’ve had to play whack-a-mole with all the errors that pop up over the past year, but it’s made citymeetings much better, and brought it to the point where I can turn meetings around within 24 hours usually.
You mentioned that you gave a talk in March of this year that laid out citymeetings, but when did the idea originally occur to you? How long ago was that? And what has the developmental timeline been like?
I was thinking about it when GPT-3 came out in 2020, and I thought if it got any better and more capable I could point it at public records. GPT-4 hit the scene in March 2023, and the capabilities were finally good enough that I thought I could probably use it for something like this.
And then GPT-4 Turbo came out in November 2023 and hit a price-to-performance context window ratio that worked really well. I was like, I can pay the cost for this out of pocket. And I think it's now possible. I just wanted to do that. That was an idea that I was excited by.
It started with me writing a newsletter in December 2023 that I called “Keys to the City Council,” where I just tried to grab as much information as possible about what the council was up to. I would grab bills, transcripts, articles, everything, and then try to write something useful by the end of the week.
This was very experimental. I'm not a journalist. I just wanted to write something interesting or useful. Journalists would look at this and think, “This is nuts. This is not how you cover the council. They exist in a broader political context you have to look at.” But that wasn't really what I was going for—I just wanted to see what I could learn.
And one thing I definitely learned: the council meetings themselves were super inaccessible. So I narrowed the scope of Keys to the City Council drastically—just to meetings. That was around the time I thought I’d give myself a forcing function and apply for School of Data in March 2024, to present my work. My proposal was accepted, so that deadline was set. The talk was in March, and by the end of April I realized I’d really overfit my methodology that I outlined in the talk to just a small group of council meetings. I was finding it challenging to publish high quality chapter every day, and so I decided to revisit my entire methodology throughout the summer of 2024.
And the summer, honestly, was this lonely period of me just doing lots of solo work. I was at my computer, just trying out tons of things, decomposing the problem in various ways, trying different prompts, building different UIs, just for me to be able to do this kind of breakdown. August was when I finally cracked the nut just enough for me to start publishing these meetings every day.
And then I decided I have to do that in September. So September was the first month where every meeting went out the same day. It was not easy because the tech still needed (and still needs) to be improved, but it was possible. And there were like 43 meetings; some were very short meetings just to vote, but some were long. The Randy Mastro hearing at the end of August was 12 hours long.
So yeah that's the timeline. I'm here now. I'm continuing to improve the tech, but my time is pretty shot. I have client work that I use to pay the bills, but I’m also putting a ton of effort into making sure citymeetings is operational. There’s significant interest now, partially because I get things up the same day. When someone who needs this information for work comes in the next morning, they’re able to rely on that data being there and being able to use it.
That segues very nicely into the question I wanted to ask next. How did you originally get your users, and who are they? Who is using this? Where did they come from?
So folks in government use it. Lobbyists use it. Journalists use it. Engaged citizens use it. I started to bring users more directly into product iteration when I realized they were using it for work. I reach out to everyone who seems to be using this for work if they sign up for email updates.
Starting in the summer of this year, I started to see emails with domain names I didn’t know, but I began to look up. Through that process I've gotten to learn the lobbying landscape, the advocacy landscape, the journalism and media landscape. There are many companies that I did not know about there.
There are also a bunch of government people. That's when I realized I might have been onto something.
So it was incumbent upon you to capitalize on the interest demonstrated by email signups, because it's not like there is an automatic link between seeing those emails on the list and then talking with these people or seeing what they need. You had to bridge that directly.
Yeah. I've just been talking to them and slowly trying to understand why it is that they're using citymeetings, what their jobs even are, how they fit in the political landscape. There's all this stuff that I truly did not understand and I was very naive about a year ago. So yeah that's been a lot of work.
And now I'm trying to convert them into a sort of early adopter program. The people who are really dedicated, who want to really see these tools develop, I want to work with them closely.
I’ve sent hundreds of emails to people who gave testimony saying, “Here's your testimony video and transcript on citymeetings. I wanted to share it with you in case you wanted to share it with your colleagues, advocates, or the public. Here's the link. If there are any errors, please let me know.”
That has led to a bunch of rich conversations and more understanding of New York's unique political landscape, and all the players who want different things and have different agendas.
So that's been a big part of how I've gotten the word out.
But now it’s growing pretty well. You were on NY1 recently. You’ve talked a little bit about email outreach, but how did the word get out in ways that mattered? It doesn’t matter if a million people know about this if none of the million care about it or use it. How did you go from a thing you were building, lonely in the summer of 2024, to where we are now? What happened?
Well the School of Data talk was awesome. That contributed a great deal to an initial wave of awareness—
Sorry to interrupt. Could you say what kind of room that was—how many people, who was there?
It was at New York City School of Data, which caps Open Data Week, which is a sort of festival that happens for a week every year that's run by BetaNYC, the open data program at the Office of Technology and Innovation (OTI), as well as an art program called Data Through Design. And for a week, they have people do talks, workshops, tours, and a lot of really interesting things. I encourage people to go check out.
But School of Data caps that week. It's a day-long conference where practitioners come and talk; it's largely civic tech, civic hackers, really the civic world broadly. There were probably about 30 to 40 people in the room for my talk. So it wasn't a huge attendance there, but the talk was really well received.
I spent a really significant amount of time preparing for it. My wife watched it many times. My parents saw it a bunch of times when I was visiting them. I invited friends over for donuts and coffee and they saw it.
I didn’t expect the talk to be received super well, but it got citymeetings on the radar of folks at OTI, journalists, and civic hackers. And a lot of people in that room worked in government. And so that kind-of buzz spread, and I got to have great conversations with people at the conference. The talk was a flare and allowed me to attract others who wanted to chat about it.
I also credit the annotated slides that I did and posted online. That was basically me doing School of Data all day long on the internet to anyone who was curious. That made the rounds in a bunch of places, and I dropped it in some Slacks I thought might like it.
Even throughout the summer I was taking calls with people and doing talks for their teams in their offices, in government and outside it.
All this got the word out among advocates, citizens, and people who have a vested interest in what happens at these city council meetings. Now they know about it and they're checking it; this set the stage for the moment that I was able to get meetings up the same day.
So all this awareness kept building, to the point where I was getting 15-20 newsletter subscribers a week in September, and then the NY1 thing came through. It’s been a very steady stream of interest since.
So from March until roughly September you built awareness, and the wheels are now turning much faster. People are realizing it's useful for their jobs, they’re checking it daily, it’s in their everyday workflow.
There's also one more thing, which is search. Search traffic is growing fast. There's a lot of people who search for this niche content. And it's largely people doing it for work.
And by work, you mean there's people inside the government, like inside administrative agencies, maybe inside the council, but also maybe journalists, lobbyists?
Yeah that's largely the professional users. I'm pretty sure people are searching for RFPs on citymeetings too. I've noted that some of the pages in which a city agency talks about a future RFP seems to be well trafficked. So I suspect people who sell to the government also use it, though I haven't made purpose-built tools for them yet.
So like the professional users, the people who show up every day who use it for work are people in government, they're journalists, they're lobbyists.
Like legislative or government affairs teams who work for an agency or something?
Exactly. Government affairs, legislative affairs, policy analysts—all these roles. There are a lot of blurred lines between them. Some of them even have those titles, but are also lobbyists, and they’re the real professional users—
—One man’s lobbyist is another man’s issue-based advocate—
—who I want to serve because this impacts their jobs. And I think there is a space to build tools that allow them to come up to speed on things that they need to know as quickly as possible. For journalists, every journalist in the city wants a scoop, and journalists don't go to city council meetings as much anymore.
Some of them will watch the hearings if they are relevant and high profile, but imagine you had someone or something monitoring all of them for you, so that when you wake up and go to work you have a digest of all the potential scoops for your review.
Those are the potential paid professional users. I have not figured out precisely what I will be serving them with, and I'm doing a lot of R&D work. I have an early adopter program where individuals working in a professional space can bring me their use cases, I talk with them, and I build things that they need against feedback.
What about the general public? Or civics school teachers…
I do want to start charging for this eventually for professional users, and they’ll get specialized tools. But I want to continue doing this work for the public interest—the boundary between paid and freely available is going to be whether you’re using this professionally or not.
If you're a civic association and you need to talk to a council member about something she said, you don't need professional tools. You can link to it on citymeetings for free. I want those capabilities to continue to be there for important issues that citizens care about. But the moment that professionals need tools, I want to be able to have them pay for it.
Where do you see citymeetings going from here?
I'm really trying to figure that out right now. I would like to fund it somehow so I can work on it full time and potentially hire a small group of people. And I want to increase coverage across public proceedings that New Yorkers care about. You can request coverage of something.
Everyone knows the city council is a thing. Fewer people know about community boards. Fewer people maybe know about the City Planning Commission, or the Loft Board. On the education side, there's Community Education Councils, and also the Panel for Educational Policy.
And then if you go to state, because state and city are so interlinked, there’s the Assembly, Senate, and state agencies. I don't know the state nearly as well, but I'm sure there are tens of agencies that I have not heard about.
There're many people who want to build tools like this, to take advantage of the evolving AI landscape and its increasing possibility. They want to build something that’s useful for the government and the civic sphere, and of course, they’d like to get paid for it if they can. What advice would you give to other civic technologists who want to create something like citymeetings—people who see what you’re doing and think “I want to do that!” They’ll have just read this interview, and they know citymeetings wasn’t developed automatically. It was a process of discovery, sales, work, and interest in the subject (here legislation).
I think the first thing I want to highlight is maybe go back and read what I did and probably not follow that exact same process. There is a tremendous amount of risk embedded in the process that I followed. And my goal when I set out on this project was actually not to create a civic tech project.
I just wanted to build it and become more in tune with New York City politics. I wanted to understand more about what's going on. I think public records generally are an interesting solution for that.
I also wanted to create a great portfolio project that I could show all my existing clients to demonstrate that I’m a credible language model practitioner. And so this would have been like a sales artifact for me.
And it continues to be, it's like a calling card. But if none of the things that we just talked about happened to citymeetings, I would have been happy.
I definitely got lucky here, but if I was to follow a process to build a successful civic tech project, I would start with understanding the user needs first. It really helps to understand the end user and why they do the things they do, what their motivations are.
And within the governmental sphere, it's so easy to take for granted. The public generally does not understand actors within government, what they do, and what they need. And that's why I do what I do.
Exactly. I've realized over the course of this year…I remember when we had our first conversation back in March of this year, I was like, “I think what Daniel is doing is cool. Somewhat academic, but a good public service.” But now I realize that there are a lot of very practical reasons why your service is valuable, not just to civic hackers, but just to everyone, because I think the other thing I've realized in these conversations with users, and with following what the city council does, is a lot of people don't know how government works generally, even if they're inside it.
They certainly know their piece of it, and they know how to navigate the relationships. They’ll always tell you politics is relationship driven, and it certainly is. And they’re also deeply creative. It requires ingenuity to figure out how to get an agenda through the system.
If you want to build a tool like citymeetings, I would recommend you go figure that out: what the government is, who the people within it are, what they need, what they do, what their jobs are, that kind of thing.
But there are very specific utilities that you can build and get users and traction around, or notoriety, depending on what it is that you want. I think one of the best examples of a tool that people use all the time in New York city is the BetaNYC boundaries tool.
It is such a basic utility to help people understand what district they are in. And I'm like, duh, this should exist. And people visit it all the time. I go to it all the time. And I think there are many tools like that, that help a lot of constituents in a very targeted way. And I think it's a lot easier for you to maybe come up with those ideas.
One idea that you came up with is surfacing all the human-generated transcripts from the city council without having to click five times for each one. That'd be great. Someone might think that project’s small, but if enough people get utility out of it, it can become a kind of calling card. And that's what you want—and then you get to talk to them, and now you've got a way to talk to those people and you can do more.
There’s a lot within the domain of public records. There are meetings, which you’re taking a huge bite out of, but there’s so much more. Government contracts come to mind as an example. You have your hands full with citymeetings, but would you encourage other people to look at public records?
I would encourage everyone to look at this. There's so much interesting work to be done here. I would welcome people to go and check it out. And if they want to talk to me, I want to talk to them.
There’s so much to do with city rules, and linking bills together with other datasets and meetings; I don't know exactly what this is going to look like. There’s also budgets. I think there's a tremendous amount of work to be done there. An interesting thing that someone told me recently: small, obscure things change in government all the time, especially in budgets. And it’s important to many people to figure out what those things are, so they can properly advocate for their needs. So being able to notify people about changes, but also track their lineage, would be another thing I want to think about.
This is the coolest use of AI I've EVER seen.